U-Net 모델의 특성 상 input image의 크기보다 모델을 거친 후 predict image의 크기가 작습니다.
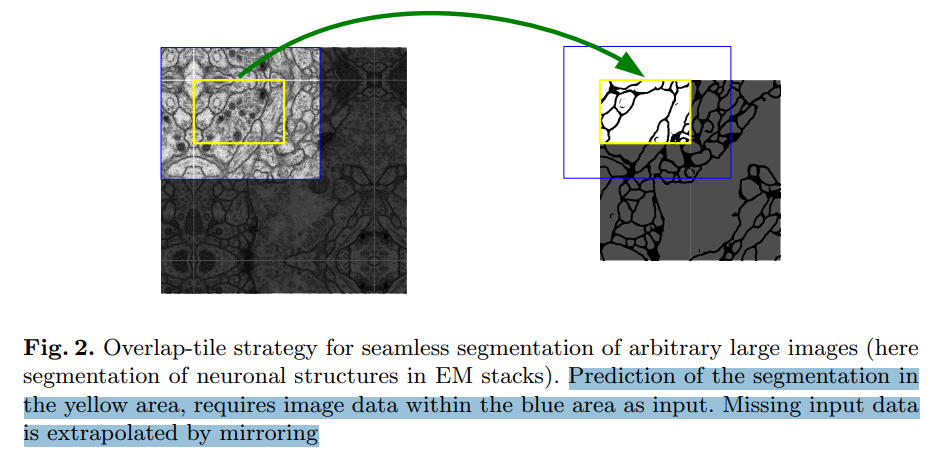
노란색 구간(388x388)을 예측하기 위해 파란색 구간(572x572)의 image입력이 필요합니다.
손실되는 입력 데이터('파란색 구간에서 노란색 구간을 제외한 부분' 중 '실제 데이터가 없이 빈 부분')는
mirroring 한 데이터로 extrapolate(외삽) 합니다.
오늘은 'Mirroring extrapolate'를 pytorch로 구현해보려고 합니다.
※ 제가 구현한 방식이 정답은 아닙니다..
해당 모델 공부를 하면서 '이런식으로 구현을 해볼수 있겠다' 라는 생각이 들어 구현을 해보았습니다.
pytorch로 모델 구현시 사용할 수 있도록 입력되는 데이터는 'torch.tensor'를 입력해주시면 됩니다.
import torch
import numpy as np
# tensor shape (1, x, y)
def mirroring_Extrapolate(img):
# mirroring 92 pixel
x = img.shape[1]
y = img.shape[2]
np_img = np.array(img)
np_img = np_img[0]
if x < 388:
pad_x_left = (572 - x) / 2
pad_x_right = (572 - x) / 2
else:
pad_x_left = 92
pad_x_right = 388 - (x % 388) + 92
if y < 388:
pad_y_up = (572 - y) / 2
pad_y_down = (572 - y) / 2
else:
pad_y_up = 92
pad_y_down = 388 - (y % 388) + 92
np_img = np.pad(np_img, ((pad_x_left, pad_x_right), (pad_y_up, pad_y_down)), 'reflect')
np_img = np_img[:, :, np.newaxis]
return torch.from_numpy(np_img.transpose((2, 0, 1)))
해당 코드로 'Mirroring extrapolated'를 진행하면 아래와 같이 이미지가 변경됩니다.
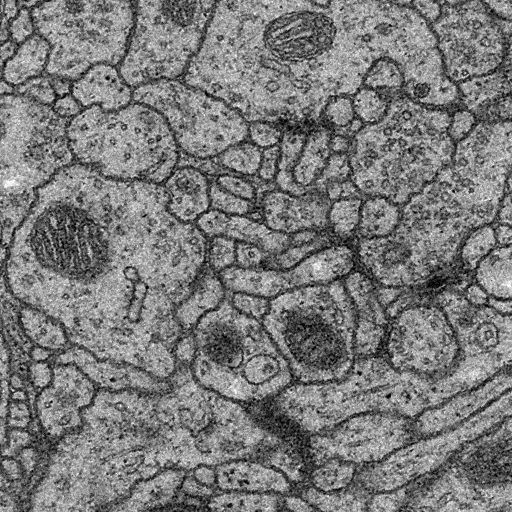
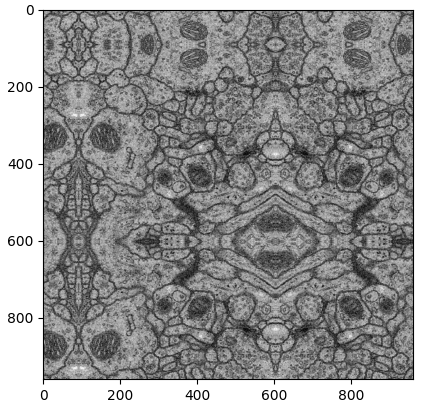
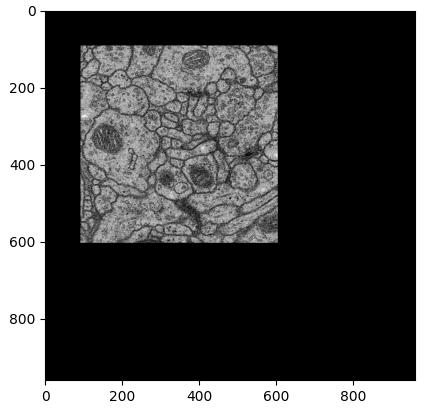
실제 input image의 사이즈(512 x 512)와 output image의 사이즈(960 x 960)의 차이가 많이 납니다.
왜 이런식으로 구현을 했는지 설명을 드리겠습니다.
U-Net이 등장하기 전 ISBI Challenge(세포나 영상의학 이미지등을 분류하는 데이터 챌린지)에서 사용하던
'sliding-window convolutional network' 방식은 아래와 같이
'이미 사용한 patch 구역을 다음 sliding window에서 다시 검증' 합니다.
이미지 출처: https://m.blog.naver.com/worb1605/221333597235
하지만 U-Net의 검증 방식은 아래와 같이 '이미 검증이 끝난 부분은 아예 건너뛰고 다음 patch 부분부터 검증'을 합니다.
이로인해 U-Net의 검증 방식이 'sliding-window' 방식보다 속도면에서 우위를 가질 수 있습니다.

이미지 출처: https://m.blog.naver.com/worb1605/221333597235
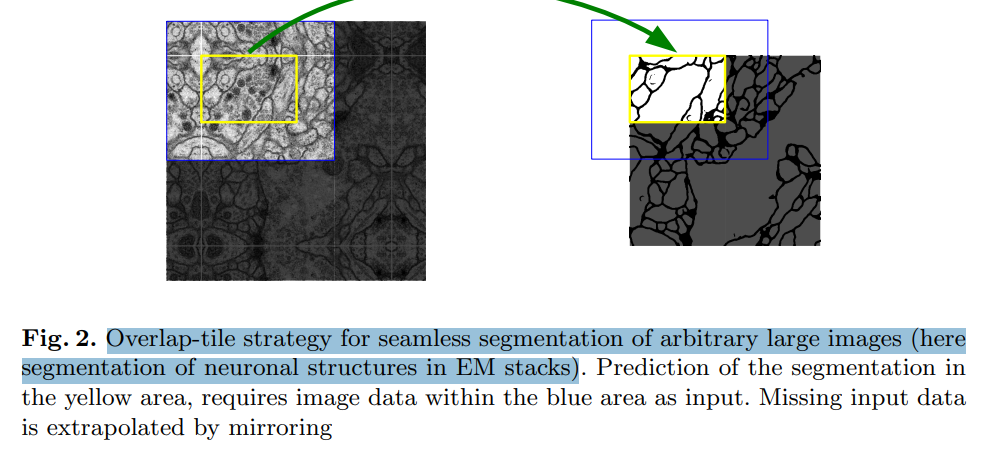
위 코드로 'Mirroring extrapolate'한 이미지를 U-Net의 검증 방식대로 구간을 나누어 보면 아래와 같습니다.

※ 파란 선이 겹쳐서 조금 보기 힘드실 수도 있습니다...
배경의 흐릿한 이미지 : 'Mirroring extrapolate'된 이미지
왼쪽 상단 선명한 이미지 : 원본 이미지
파란색 사각형 구간 : 모델에 Input 되는 이미지(572 x 572)
노란색 사각형 구간 : 파란색 사각형 구간이 Input 되었을 때 Output 되는(Segmentation) 이미지 구역
위 이미지를 보면 아시겠지만 실제 검출되는 구역(노란색 구역)은 겹치지 않지만
입력되는 이미지 구역(파란색 구역)은 겹치게 됩니다.
해당 현상은 논문상 'Overlap-tile strategy'라고 정의되어있습니다.
제가 생각한 바로는 '이미지의 input size가 모델의 output size(388 x 388) 보다 큰 경우' 위와 같이
'Mirroring extrapolate' 방식으로 이미지를 tile로 나누어 output size를 (388 x 388)에 맞춘 후
※ Input image 한장에 여러번 학습을 진행하거나
=> label 데이터도 ‘Mirroring extrapolate’ 한 뒤 노란색 사각형 구간을 Crop 하여서
※ Input image 한장에 한번 학습을 진행하거나
=> Input image의 size와 같게 output data를 concat하여서
'두 방식을 모두 사용해볼 수 있다' 라고 생각하였습니다.
위 부분도 코드로 구현이 완료되면 포스팅 하도록 하겠습니다.
'AI' 카테고리의 다른 글
| (U-Net) pytorch로 Mirroring Extrapolate를 적용하여 학습하기 (0) | 2022.05.18 |
|---|---|
| (CycleGAN) pytorch로 CycleGAN의 Generator / Discriminator 구현 (0) | 2022.04.14 |
| (U-Net) 모델 분석 및 Pytorch로 구현 - 1 (2) | 2022.04.12 |
| (Pytorch) Linear Regression, Multiple Linear Regression (0) | 2022.04.06 |